[N] Głośność odczuwalna dla podcastu - jak to ustawić?
O ustawianiu głośności już kiedyś pisałem, a chociaż dotyczyło to muzyki, to teoria i narzędzia zostają te same, zmieniają się tylko wartości docelowe. Dzisiaj chciałbym postarać się odpowiedzieć na pytanie, jak ustawić głośność nagrania podcastowego przed publikacją, by nie odbiegało ono znacząco głośnością od innych podcastów. Bowiem - nieco inaczej niż w muzyce - nam, podcasterom, nie powinien przyświecać cel stłamszenia głośnością innych podcastów, tylko takie wpasowanie się, by to słuchacz miał komfort słuchania wszystkiego bez ruszania regulacji głośności. Przynajmniej takie jest moje zdanie - zdecydowanie nie cierpię tzw. loudness war i ustawicznej walki producentów, żeby "oszukać system" i wysforować się głośnością przed innych...
Jaka ta głośność?
Rzecz w tym, że do końca nie wiadomo, jaką dokładnie głośność ustawiać, bo jednej oficjalnej normy nie ma. Teoretycznie mogłyby obowiązywać zapisy z normy ITU-R B.S. 1770, które przewidują dla radia i telewizji wartość -23LUFS (dla Europy, -24 dla reszty świata). Ale podcast to nie radio, bliżej mu do mediów strumieniowych. Tutaj również nie ma zgody - część platform przyjęła wartość -14LUFS, inni znów -16LUFS, przy czym dotyczy to głównie muzyki. Ot, ustalenia wielkich korporacji, do których reszta świata chcąc nie chcąc musi się dostosować.
Jeśli chodzi o podcasty jako takie, to również nie ma pełnej zgody. Niektórzy mówią o standardzie -18LUFS, podczas gdy platformy publikujące podcasty (np. Castos czy BuzzSprout) najczęściej posługują się dwiema wartościami: -16LUFS dla plików stereo i -19LUFS dla plików mono.
No, a jeśli jest bałagan, to znów trudno o ustalenie jakiejś wspólnej wartości - czy w ogóle można mówić o standardzie w takim przypadku? I w ogóle jak sprawić, by nasze nagranie miało dokładnie taką, a nie inną odczuwalną głośność, reprezentowaną przez konkretną liczbę LUFS?
Ustawianie LUFSów
Wyprodukowanie pliku o określonej głośności LUFS bywa kłopotliwe. Wszystko przez to, że LUFS (zintegrowane, które nas interesuje) trzeba mierzyć dla całego materiału (utworu, audycji), bo taki jest jej sens. Wprawdzie edytory audio (takie jak Acon Acoustica, Adobe Audition, RX Audio Editor, WaveLab Elements 11 czy nawet Audacity) mają dostępną odpowiednią funkcję normalizacji głośności, ale z jej wykorzystaniem czasem bywa kłopot.
O Adobe Audition nie będę się wypowiadał, bo nie używam regularnie tego programu. Natomiast w pozostałych przeprowadzałem testy i tylko połowicznie byłem zadowolony. Idealne do normalizacji głośności są Reaper, RX Audio Editor oraz WaveLab Elements 11. W nich można przeprowadzić normalizację do zadanej głośności z uwzględnieniem wartości szczytowych (true peak).
I jeszcze taka, może oczywista, uwaga: normalizacji dokonuje się na samym końcu procesu obróbki. Mamy już wtedy gotowy odcinek, zmiksowany, z muzyką, dźwiękami itp. To ostatni krok przed publikacją odcinka i jego zadaniem jest przede wszystkim dopasowanie parametrów pliku dźwiękowego do "standardów" platformy, na której publikujemy podcast. Jeśli używamy komercyjnej platformy, warto poszukać w sekcji FAQ lub pomocy, jakie dana platforma ma wymagania jeśli chodzi o głośność - być może będą się one różniły od przyjętych przeze mnie -16LUFS dla plików stereo i -19LUFS dla plików mono. Jeśli kogoś ciekawi, dlaczego wartości są różne dla plików stereo i mono, może poczytać sobie o tzw. Pan Law.
Korekta fazy
Zanim jednak będziemy majstrować przy głośności, warto przyjrzeć się naszemu plikowi audio. Często zdarza się, zwłaszcza w przypadku nagrań głosów męskich, że dostrzegamy wyraźny brak symetrii między częścią "górną" a "dolną" graficznego odwzorowania sygnału audio:

Brzmieniowo nic złego się w tym wypadku nie dzieje, ale jeśli zmierzymy wartości szczytowe, to okaże się, z jednej strony najgłośniejszy "pik" ma aż o 3dB większą wartość:

Warto w takim wypadku skorzystać z funkcji adaptacyjnej zmiany fazy, mają ją wbudowaną Acon Acoustica czy RX Audio Editor. Przywróci to symetrię i zyskamy 1-3dB na zapasie głośności.
Jeśli kogoś ciekawi, skąd się owa asymetria bierze, to po więcej szczegółów odsyłam do filmu Pana Tomasza Wróblewskiego z kanału 0dB.
Acon Acoustica
Wczytałem do programu nagranie z rejestratora Tascam. Średni poziom głośności tego nagrania to -30,4LUFS, czyli sporo za mało na publikację. Jednocześnie w pliku widać bardzo wyraźne "szpilki", które sięgają -10dB, a nawet -6dB (widać już plik po zastosowaniu adaptacyjnej korekcji fazy - została przywrócona symetria):

Wejdźmy teraz do okna normalizacji - wybieramy normalizację zgodnie ze standardem ITU-R BS.1770 (EBU R-128), normalizujemy do -19LUFS, czyli przyjętego "standardu podcastowego" dla plików monofonicznych:

Oto, jak będzie wyglądał plik po takiej normalizacji:

Oczywiście, pojawiło się przesterowanie i chociaż plik faktycznie ma zakładane -19LUFS, to jednak nie nadaje się do publikacji z uwagi na lokalne przesterowania (clipping). Wycofałem zmiany i przeprowadziłem kompresję, żeby pozbyć się zbyt dużej dynamiki nagrania:

Ponowienie normalizacji tym razem dało oczekiwane rezultaty - plik ma zakładaną głośność i ani jednego przesterowania. Warto tylko przepuścić go przez jakiś limiter, aby utemperować szczytowe wartości do -1dB (ogólnie przyjęło się, aby wartość true peak nie przekraczała tej wartości - i tu przynajmniej wszyscy są zgodni, choć czasem mowa o -2dB):

Dopiero po tych operacjach plik nadaje się do publikacji. Podobnie wygląda obróbka w programie Audacity - jest tam polecenie Loudness normalization, gdzie można podać docelową wartość odczuwalnej głośności w LUFS, jednak w przypadku plików o sporej dynamice (jak ten powyżej) doprowadzi to zwykle do przesterowań i trzeba przeprowadzić podobne kroki, tzn. najpierw sygnał skompresować, a dopiero później normalizować. Audacity ma jednak pewną alternatywną możliwość - ze względu na wewnętrzne 32-bitowe przetwarzanie, można zrobić najpierw normalizację, a potem zbyt głośne fragmenty ściszyć za pomocą limitera. Ten sposób jest o tyle łatwiejszy, że nie trzeba cofać i ponawiać operacji, gdyby zrobiona wcześniej kompresja okazała się zbyt słaba.
Przy okazji zwrócę uwagę, że zwykle "zabawa" w kompresowanie materiału na tym etapnie nie jest potrzebna i powyższy przykład jest celowo przejaskrawiony, żeby zwrócić Waszą uwagę na ewentualne problemy. Kompresję najczęściej robi się wcześniej i do normalizacji trafia już plik o mniejszej dynamice, gdzie aż tak dużych "pików" się nie spotyka.
RX Audio Editor
Przyznam, że w edytorze RX Audio Editor, dostępnym w wersji Standard pakietu RX, normalizacja głośności podoba mi się najbardziej, choć samo okienko Loudness Control, które za nią odpowiada, jest dość niepozorne i przez długi czas używałem go tylko do pomiarów głośności, a nie jej ustawiania:

Wystarczy jednak wpisać odpowiedni poziom LUFS oraz oczekiwany poziom wartości szczytowych true peak i... tyle. Testowy plik przed obróbką wyglądał tak:

zaś po obróbce ma już oczekiwane parametry:

Różnica polega głównie na tym, że nie musimy się martwić ewentualnymi przesterowaniami - Loudness Control w razie czego zastosuje limiter, który ściszy automatycznie najgłośniejsze "piki". Naszym zadaniem jest jedynie wskazanie oczekiwanej głośności docelowej i odczekanie chwilki, aż program upora się z obliczeniami...
WaveLab Elements 11
Podobnie mają się sprawy w WaveLab Elements 11 (we wcześniejszych wersjach nie było podobnej funkcji). Klikamy na przycisk Loudness, który wyświetli nam okienko ustawień, jakie chcemy uzyskać:

Oryginalny plik prezentuje się następująco:

Po ustawieniu -19LUFS i zapasu -1dB dla wartości szczytowych program bez szemrania wykonuje potrzebne operacje i otrzymujemy gotowy plik:
Reaper
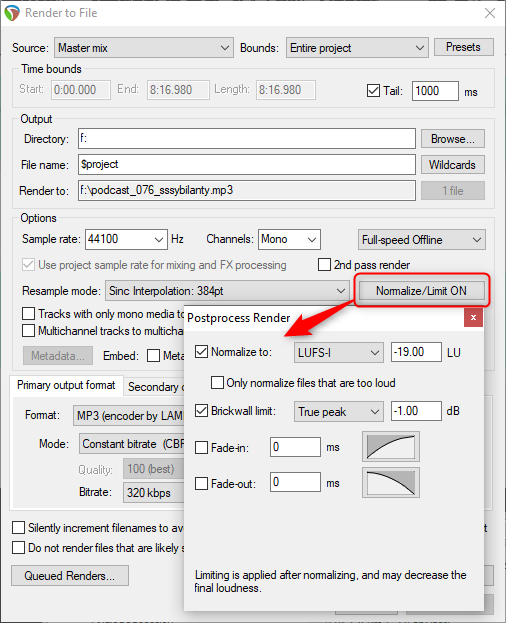
W Reaperze sprawa wygląda obecnie bardzo prosto. Otóż docelową normalizację możemy przeprowadzić w momencie renderowania całego projektu - wystarczy tylko wyświetlić odpowiedni panel w oknie renderowania i wpisać tam żądane wartości, a Reaper najpierw stworzy plik wynikowy, przeanalizuje go i dokona odpowiedniej normalizacji:
Prace ręczne
Oczywiście, jeśli nie mamy do dyspozycji automatu, trzeba rzecz załatwić ręcznie. Czyli po prostu zmieniać głośność i ją mierzyć. Idea zintegrowanego LUFSa zakłada pomiar dla całości utworu, ale jeśli nie ma dużych wahnięć głośności, np. długich okresów ciszy, to można sprawdzać na krótszych fragmentach za pomocą "Short-term" LUFS - mniej więcej powinno się zgadzać, zintegrowany LUFS zwykle wyjdzie nieco niższy, bo uwzględni też przerwy (pauzy). Większość programów do edycji dźwięku ma już (chyba?) mierniki LUFS, a jeśli nawet nie, zawsze można się ratować darmowymi wtyczkami w rodzaju Youlean Loudness Meter czy Voxengo SPAN.
Najlepiej w tym przypadku użyć po prostu limitera z wbudowanym miernikiem LUFS - wtedy po prostu zwiększamy głośność limiterem i patrzymy, czy osiągamy zakładany poziom LUFS. Po przetworzeniu należałoby jeszcze cały plik sprawdzić, czy faktycznie ma taką głośność, jak powinien. Przyznam, że trochę to mozolne, ale i też nie musimy trafić z głośnością dokładnie co do jednej dziesiątej - wahnięcie 1 czy nawet 2 LUFS w którąś stronę to nie tragedia (chociaż im mniej, tym oczywiście lepiej).
Warto!
Myślę, że warto pilnować spójnej głośności w swoich podcastach, po prostu jest to wygodniejsze dla słuchaczy, który mogą sobie przeskakiwać z odcinka na odcinek bez konieczności regulacji głośności (pamiętajmy, że często podcasty są odsłuchiwane w warunkach, gdzie szybka regulacja głośności bywa kłopotliwa!).
Co do utrzymania jednakowej głośności z innymi podcastami - może być różnie, bo jak pokazały moje wyrywkowe testy, głośności te kształtują się od -23 do -14LUFS, więc rozpiętość jest spora. Stąd myślę, że zasada -19LUFS dla plików mono, a -16LUFS dla stereo jest całkiem rozsądna i pozwoli nam nie różnić się tak bardzo od innych audycji.
Komentarze
Prześlij komentarz